— Research Brief
AEO and SEO for Enterprise in 2026: What the Research Actually Says
How AI answer engines actually decide what to cite, what has stopped working, and 50 high-value questions enterprise buyers are asking that nobody currently owns. A research brief from Dotfusion.
Search is fracturing. Not gradually, not theoretically. Right now, for enterprise buyers in your target market.
SparkToro's June 2026 study found that 68% of US Google searches end without a click to the open web, up sharply from 2024 levels. AI Overviews appear in roughly 35% of searches overall and up to 80% of problem-solving searches. The synthesized answer is replacing the blue link list, and the content that earns a place in that synthesized answer is not selected by the same logic that determines organic rank.
This brief compiles what we know, as of April 2026, about how AI answer engines actually decide what to cite, what structural and content decisions move the needle, and where the highest-value whitespace sits for enterprise brands. It is based on a cross-analysis of published research from Ahrefs, AirOps, Amsive, Discovered Labs, iPullRank, and others, alongside practitioner data from our own client work and site audits.
Nothing in here is speculative. Where something is an emerging signal rather than confirmed behavior, we say so.
The Core Shift: Two Things Happening at Once

Before getting into tactics, it is worth being precise about what is actually changing, because the two forces at work are related but distinct.
Force one: AI answer engines are absorbing informational queries. The consequence is that content designed purely to capture awareness-stage search traffic is being disintermediated. If your content strategy is built around broad educational articles, AI is now answering those questions directly. The audience for that content is contracting.
Force two: The Invisibility Gap. Only 12% of AI citations overlap with Google's top 10 organic results. Strong Google rankings do not guarantee AI visibility. You can rank number one for a term in Google and be completely absent from every ChatGPT answer, every Perplexity summary, and every Gemini response your buyers are reading before they open a browser tab.
The strategic implication: SEO and Answer Engine Optimization (AEO) are related but separate problems. You need both, and you need to understand what drives each. Critically, a mid-2025 analysis found that 97% of AI Overview citations came from pages already ranking in the top 20 organic results, which made traditional SEO the prerequisite, not the solution. Ahrefs' data after the Gemini 3 update shows AI Overviews now pull just 38% of citations from Google's top 10, so the coupling between rankings and AI Overview citations is loosening.
How AI Engines Actually Decide What to Cite
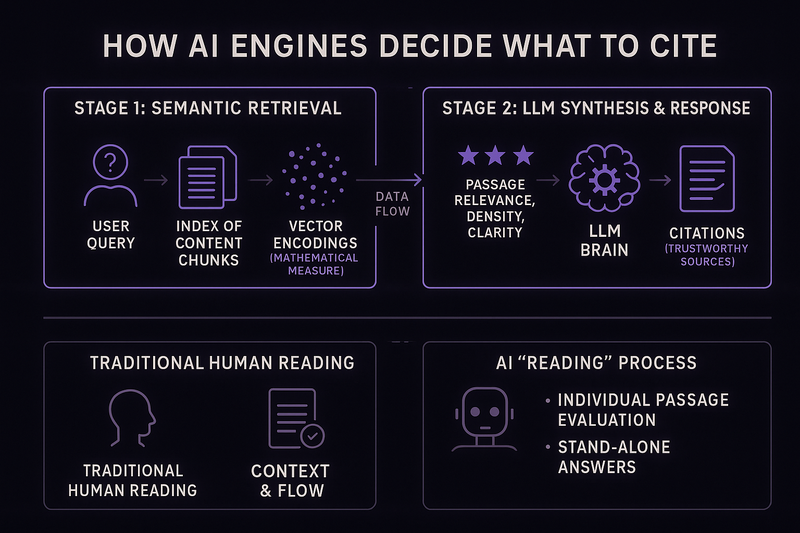
The RAG Mechanism
All major AI answer engines (ChatGPT, Perplexity, Gemini, Claude) use a process called Retrieval-Augmented Generation as their core retrieval mechanism. Understanding it changes how you think about content architecture.
The process works in two stages. First, the system queries an index and retrieves semantically relevant passages using vector embeddings, a mathematical measure of how closely a content chunk matches query intent. Second, the LLM synthesizes the retrieved passages into a response, citing sources it deems trustworthy.
The practical consequence: AI engines do not read your page the way a human does. They extract passages and evaluate each one independently for relevance, information density, and structural clarity. A page that reads well as a whole can still fail at the passage level if individual sections do not stand alone as self-contained answers. This is a structural content architecture problem, not a writing problem.
Query Fan-Out: The Multiplier Most Brands Are Missing
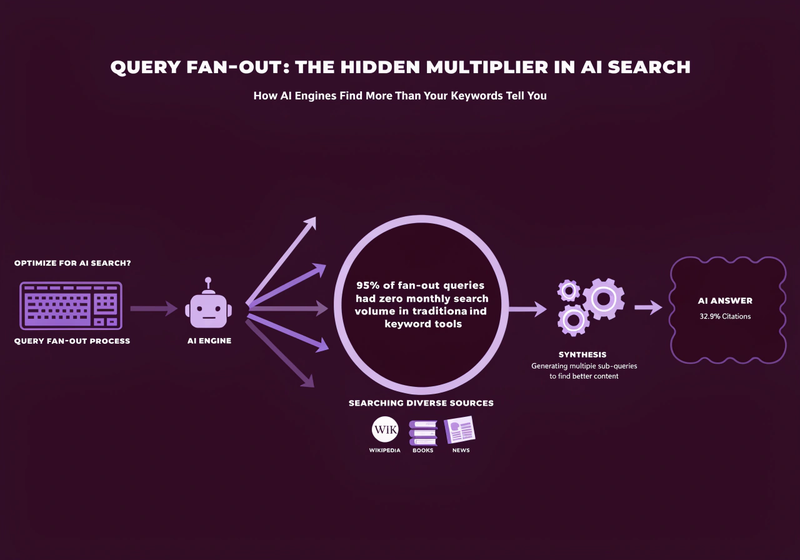
When a user types a prompt into ChatGPT or Perplexity, the system does not run a single search. It generates multiple sub-queries from that prompt and pulls from those sub-query results. This is called query fan-out.
- Google AI Mode: 8-12 sub-queries per prompt
- ChatGPT: 4-20 sub-queries depending on complexity
- Perplexity: 3-8 sub-queries
AirOps analyzed 15,000 ChatGPT prompts and found that 89.6% of searches generated two or more fan-out queries, 32.9% of cited pages were only discovered through fan-out, not the original query, and 95% of fan-out queries had zero monthly search volume in traditional keyword tools.
Read that last number carefully. Most of the queries AI engines are actually running to build their responses are invisible to keyword research tools. The content that answers those questions either exists on your site or it does not.
Platform-by-Platform Citation Behavior
Each AI engine has meaningfully different citation behavior. Treating them as a single channel is a strategic error.
| Engine | Favors | Key Signal |
|---|---|---|
| ChatGPT | Wikipedia (47.9% of top citations), authoritative aggregators | Domain authority (~30% weight); neutral, encyclopedic framing |
| Perplexity | Real-time sources; structured content | Content updated within 30 days gets 3.2x more citations; freshness weighted at ~40% |
| Gemini | Google ecosystem, Knowledge Graph-verified entities | E-E-A-T weighted at ~35%; FAQPage schema produces direct lift |
| Claude | Technical precision, conservative citation habits | Formal, authoritative tone; B2B-technical content preferred |
| Google AI Mode | 3,621 unique domains per query | Only 13.7% URL overlap with AI Overviews despite 86% semantic similarity |
One data point worth highlighting: ChatGPT referrals convert at 15.9% versus 1.76% for Google organic. The volume is still small, but the quality of that traffic is extraordinary.
The Atomic Q&A Architecture: What the Data Actually Supports

Why Shorter, Focused Content Earns More Citations
An Ahrefs analysis of 174,000 AI Overview citations found 53.4% went to pages under 1,000 words. The correlation between word count and citation position was effectively zero. AI engines are not looking for long, comprehensive guides. They are looking for extractable, self-contained answers.
Pages with question-format headings following answer-first structure are 2.8x more likely to earn AI citations. A January 2026 case study from Discovered Labs built 66 AI-optimized articles targeting specific buyer questions. AI-referred trials grew from 575 to 3,500+ in seven weeks, a 600% citation uplift across ChatGPT, Claude, and Perplexity.
The Format That Consistently Works
The content format that earns citations follows a consistent structure:
- H1: Exact question, long-tail and specific, mirrors how someone would type or speak it
- Opening paragraph: 40-70 word direct answer, self-contained, no forward references
- H2 sections: Supporting context, related sub-questions, each independently extractable
- Related Questions section: 3-5 internal links to adjacent content in the same topic cluster
- Footer: Author with credentials, datePublished, dateModified
Total word count sweet spot: 600-1,200 words. The critical caveat: "atomic" refers to the precision of the question, not the scarcity of the content. 500 words is the floor for genuine supporting depth.
The Highest-Value Target Questions Are Zero-Volume
Because 95% of AI fan-out queries have zero monthly search volume in traditional keyword tools, the highest-value questions to build content around often come not from keyword research but from actual sales conversations. These questions have near-zero keyword volume and maximum commercial intent.
Examples of the kind of question that falls into this category:
- "Can a headless CMS handle property data feeds for a REIT?"
- "How do I justify a headless CMS migration to my CFO?"
- "Does headless CMS improve content governance for a distributed marketing team?"
Nobody builds content for these questions because no keyword tool surfaces them. That is exactly why they are worth building.
Structured Data and Schema: What Changed in 2026
What Google Deprecated
- January 2026: FAQ rich results in SERPs (the schema itself still aids AI extraction)
- February 2026: HowTo rich results
- June 2025: CourseInfo, ClaimReview, EstimatedSalary, LearningVideo, SpecialAnnouncement, VehicleListing, Book Actions
What to Prioritize Now
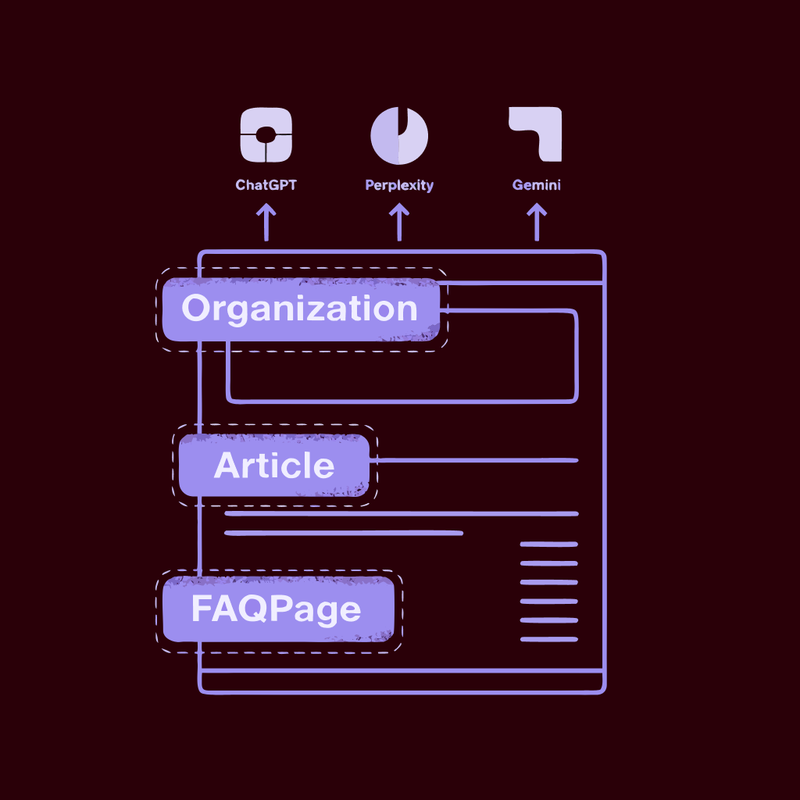
Organization with sameAs, legalName, logo, and knowsAbout fields is the highest-leverage schema for entity disambiguation and AI trust. Deploy it site-wide in the footer.
Person for authors with alumniOf, affiliation, hasCredential, knowsAbout, and sameAs is critical for E-E-A-T signals. Every piece of content targeting AI citations needs a linked, credentialed author.
Article / BlogPosting is required for any content targeting AI citations. Headline must match H1 exactly. datePublished and dateModified are non-optional.
FAQPage remains valid for AI extraction despite the SERP display deprecation. Google removed the rich result display in January 2026. The schema itself still functions as an extraction signal for ChatGPT, Perplexity, and Gemini. Do not remove it.
SpeakableSpecification is underused and worth implementing now. It flags content suitable for audio playback, with forward-looking value for voice and multimodal search.
An important calibration from Lily Ray (Amsive): schema predicts only 4-7% of AI citation behavior. It is a hygiene factor, necessary but not sufficient. The bigger levers are topical authority, E-E-A-T, and content structure. 65% of pages cited by Google AI Mode and 71% cited by ChatGPT include structured data. That is the floor, not the ceiling.
Entity Optimization: How AI Engines Decide Who to Trust

AI engines think in entities, not keywords. A brand entity that is clearly defined, consistent, and externally validated is one an AI can cite without risking a hallucination.
The four-part entity playbook:
Consistency: Unify brand name, address, phone, and description across website, Wikipedia, LinkedIn, Google Business Profile, G2, Trustpilot, and Crunchbase. Mismatched data across sources reduces AI trust.
Structure: One primary entity per page. Organization schema with @id and sameAs links to authoritative external profiles. Use knowsAbout to declare topical authority.
Authority: Build co-occurrence with relevant industry terms. Earn mentions from recognized external sources. Publish original research that requires others to cite you.
Visibility: Monitor Knowledge Panel accuracy. Track entity appearance in AI Overviews and AI Mode.
Wikipedia's role here is outsized. It appears in 28.9% of AI Mode citations and 18.1% of AI Overview citations. For brands without a Wikipedia presence, the next best anchors are Crunchbase, LinkedIn company pages, and verified trade directories like Clutch and Agency Spotter.
There is also a reciprocal mentions pattern: when Brand A mentions Brand B and Brand B mentions Brand A, AI systems cite both more confidently. Co-marketing, partner content, and industry roundups are not just distribution plays. They are entity trust signals.
llms.txt: The Honest Picture
There is a lot of noise around llms.txt. Here is what is actually confirmed versus what is not.
What is not true: llms.txt does not improve Google search rankings. John Mueller confirmed this repeatedly in 2025. No major AI provider has officially committed to parsing llms.txt in production systems as of Q1 2026. It cannot prevent AI crawlers from accessing your content.
What has signal: OpenAI's and Microsoft's crawlers are actively fetching llms.txt files (Profound research). Google included an llms.txt file in its Agent-to-Agent protocol, suggesting relevance for agent-to-agent communication even if Search does not use it for rankings. The strongest validated use case is developer tooling: AI coding assistants retrieve documentation in real time, and llms.txt helps them find the right pages with less token waste.
What matters more: AI bot governance in robots.txt. Many enterprise sites have legacy User-agent: * Disallow: / rules that inadvertently block all AI crawlers. This is a high-priority audit item.
| Bot | Owner | Recommendation |
|---|---|---|
| OAI-SearchBot | OpenAI | Allow: surfaces content in ChatGPT answers |
| GPTBot | OpenAI | Strategic: does NOT affect current ChatGPT citations; training data only |
| Claude-User | Anthropic | Allow |
| PerplexityBot | Perplexity | Allow |
| ClaudeBot | Anthropic | Block if preferred (training scraper, not retrieval) |
| Google-Extended | Strategic: may improve Gemini-specific citation |
Adding an AI crawler robots.txt audit to every technical SEO engagement is now a standard deliverable. One hour of work with compounding impact.
E-E-A-T in the AI Era

E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) is the signal LLMs use to determine which sources they can safely cite. Experience has emerged as the hardest signal to fake and the highest-leverage differentiator.
Experience: First-person insights, original data and charts, case studies with specific verifiable outcomes. The December 2025 Core Update explicitly rewarded experience. Sites using mass-produced generic text saw visibility drops of up to 71%.
Trustworthiness (flagged by Google as the most critical component): HTTPS, accurate site information, transparent privacy policy, outbound citations to primary sources, consistent entity data across the web, and third-party certifications displayed on site.
E-E-A-T is not just a content consideration. For teams building enterprise CMS platforms, it is a build deliverable. Mandatory author pages with Person schema, credential markup, and verified external profile links should be standard on every enterprise web build.
Content Freshness: Not Optional for AI Visibility

Content updated within the last 30 days gets 3.2x more Perplexity citations than older material. Freshness contributes approximately 18-22% weight in AI citation decisions for rapidly evolving topics.
A three-year-old post with a substantive update can begin appearing in ChatGPT responses within two weeks. CloudEagle refreshed 33 pages and achieved 3x AI citations and 113% organic clicks in 12 weeks.
The practical freshness architecture:
- Update
dateModifiedin Article schema every time substantive changes are made - Add explicit freshness annotations: "Updated April 2026: New data on [topic] added."
- Replace vague temporal language: "recently" becomes "in Q1 2026"; "growing trend" becomes "up 35% year-over-year"
- Prioritize pages with statistics over 12 months old for refresh cycles
- Recommended cadence: every 60-90 days for priority pages
Content freshness maintenance is a natural fit for agentic content operations: automated monitoring of pages with stale statistics, followed by targeted refresh cycles.
Technical Decisions That Affect AI Crawlability
Server-side rendering is an AEO prerequisite. AI bots do not render JavaScript reliably. JavaScript-only pages are invisible to most AI crawlers. A headless frontend built with Next.js or Nuxt using server-side or static generation is inherently better positioned for AI crawlability than a JavaScript-heavy SPA. This is a build decision, not a content decision, which is why it needs to be made at the architecture stage.
Orphan pages get low crawl priority. Pages with no internal links receive minimal crawl attention. 5-10 contextual internal links per page, with keyword-rich anchor text, is the current standard. Semantic, descriptive URLs receive 11.4% more AI citations than non-descriptive ones.
Organization schema in the footer with complete entity information is estimated to improve brand citation frequency by 15-20% for informational queries. One implementation, compounding benefit.
Core Web Vitals targets for 2026:
- LCP: under 2.5 seconds
- INP (replaced FID): under 200ms
- CLS: under 0.1
PDFs as indexed content are underused. AI bots parse PDFs easily. Technical documentation and whitepapers published as indexed PDFs create additional citation surface area beyond HTML pages.
What Has Already Stopped Working
| Tactic | Status |
|---|---|
| Keyword stuffing | Actively penalized |
| Scaled AI content without genuine expertise | Up to 71% traffic drops (March 2026 Core Update, 600,000 pages analyzed) |
| TOFU informational content as a standalone strategy | Being disintermediated by AI summaries |
| Google-only SEO strategy | Organic rank ≠ AI citation |
| llms.txt as a primary AEO lever | No confirmed citation benefit in current production systems |
| Anonymous, unattributed content | Explicitly targeted by December 2025 Core Update |
| Buying links / PBNs | Manual penalties; ~750,000/month issued by Google |
Critical nuance on AI-generated content: The March 2026 Core Update data shows near-zero correlation (0.011) between AI use and ranking penalties. The signal is quality and originality, not the tool. AI content demonstrating genuine expertise and original data is not penalized. Generic AI-generated summaries of other summaries are.
50 Questions Enterprise Buyers Are Asking That Nobody Currently Owns in AI Engines

These 50 questions were mapped by intent, target channel (Google vs. AI engines), and current content coverage across the enterprise web. The ones marked as whitespace have no authoritative answer currently dominating AI engine citations.
Problem and Pain Awareness
- Why does publishing content on our enterprise website always require a developer?
- Why is our CMS holding back our marketing team?
- What are the signs your enterprise website is costing you revenue?
- How much does enterprise technical debt in a legacy CMS actually cost?
- Why can't our content team update the website without IT?
- What happens to SEO when your CMS becomes a bottleneck?
- How do I know if it's time to migrate away from WordPress?
- Why is our Sitecore or AEM platform so expensive to maintain?
- What are the real costs of staying on a monolithic CMS?
- Why do enterprise replatforming projects fail?
Solution and Category Questions
- What is headless CMS and is it right for enterprise?
- What is composable architecture and how is it different from headless?
- What is MACH architecture and should my enterprise use it?
- What is agentic content operations? (whitespace: nobody owns this in AI engines)
- What is a content supply chain and how does it work for enterprise?
- What is the difference between headless CMS and a DXP?
- How long does a headless CMS migration take for an enterprise?
- What is an API-first architecture and why does it matter for content?
- What is structured content and how does it enable omnichannel publishing?
- What is content modeling in headless CMS and why does it matter?
Vendor Evaluation Questions
- How do I choose a headless CMS agency for an enterprise project?
- What should I look for when evaluating CMS implementation partners?
- How much does headless CMS development cost for mid-to-large enterprise?
- What is the ROI of migrating to headless CMS?
- How do I build the business case for a CMS migration?
- Should my enterprise hire an agency or build headless CMS in-house?
- What does a headless CMS agency actually do on a project?
- How do I write an RFP for a headless CMS development project?
- What questions should I ask during a headless CMS agency discovery call?
AEO and Discoverability Questions
- What is Answer Engine Optimization (AEO) and how is it different from SEO?
- How do I get my website cited by ChatGPT or Perplexity?
- What is llms.txt and why does my website need one?
- What structured data does my website need to show up in AI answers?
- How do Google AI Overviews decide which websites to cite?
- How do I check if my company is showing up in ChatGPT answers?
- How do I optimize my content to be cited by AI search engines? (whitespace)
- What is GEO (Generative Engine Optimization) and how does it relate to AEO?
- Why is my enterprise website invisible to AI answer engines?
Content Operations Questions
- How do I scale content production without increasing headcount? (see our enterprise content operations guide)
- What is an agentic content workflow for enterprise marketing teams? (whitespace)
- How do enterprise teams manage content across multiple regions and languages? (see our enterprise content operations guide)
- What is a content operations maturity model?
- How do I automate content publishing across multiple channels from a single CMS? (see our enterprise content operations guide)
- What AI tools are enterprise content teams using to scale production in 2026?
Competitor and Comparison Questions
- Contentful vs Storyblok: which is better for enterprise?
- Contentful vs Agility CMS for Canadian enterprise
- WordPress vs headless CMS: when should enterprise migrate?
- Adobe AEM vs headless CMS: the case for migrating
- Sitecore vs headless CMS: the case for migrating
- Which headless CMS is best for commercial real estate platforms?
A Prioritized Starting Point
Given the whitespace and effort tradeoffs, here is where to focus first.
Immediate fixes (existing content, no new writing):
- Audit robots.txt to confirm OAI-SearchBot, Claude-User, and PerplexityBot are explicitly allowed
- Add FAQPage and Article schema to all CMS service pages
- Update dateModified on all pages with statistics older than 12 months
- Ensure all author pages have linked Person schema with credential markup
First content priorities (publish before competitors do):
- "What is agentic content operations?" Nobody owns this in AI engines right now. The window is open
- "What is a content supply chain and how does it work for enterprise?" Active search impressions with no authoritative answer available
- "How do I get my website cited by ChatGPT or Perplexity?" High conversion intent for any agency doing AEO work
Entity authority (two hours of work, compounding benefit):
- Register on Clutch, G2, and Agency Spotter with consistent entity data matching the website
- Verify all external profiles (LinkedIn, Crunchbase) use identical brand name, description, and address
Ongoing:
- Quarterly content freshness audit: flag all pages with statistics over 12 months old and update them
- Build a custom GA4 channel group tracking referrals from chatgpt.com, perplexity.ai, claude.ai, and gemini.google.com. This is the measurement layer that makes everything else legible
Measurement
| Metric | Tool | What to Track |
|---|---|---|
| Organic rankings (top 20) | Google Search Console | Core prerequisite for AI visibility |
| AI citation frequency | Ahrefs Brand Radar, Profound, Peec AI | Track separately per ChatGPT, Perplexity, Gemini |
| AI-referred traffic | GA4 custom channel group | Benchmark: ChatGPT referrals convert at ~15.9% |
| Referring domains | Ahrefs | Compounding authority indicator |
| Non-branded click share | GSC | Indicator of content reaching new audiences |
How We Approach This at Dotfusion

The reason we built this brief is that discoverability is not a post-launch service for us. It is engineered into the website from the first architecture conversation.
The structural decisions made during a headless CMS build (content modeling, schema architecture, server-side rendering, author entity markup, robots.txt governance) determine whether a site earns AI citations or not. Retrofitting those decisions after launch is significantly harder and less effective than making them correctly at the start.
This research informs how we build: every page structured for passage-level extraction, every author credentialed and schema-linked, every build reviewed for AI crawler accessibility. The 50 questions above are the kind of content gaps we help enterprise clients identify and close after launch as part of content operations.
If you want to talk through where your site sits against this framework, that conversation starts here.
Research sources: Lily Ray / Amsive (February 2026), Ahrefs (174,000 AI Overview citations study), Discovered Labs (B2B SaaS case study, January 2026), JetDigitalPro / March 2026 Core Update analysis (600,000 pages), AirOps (15,000 ChatGPT prompts analysis), Google Search Central (December 2025 update), Wellows, Peec AI, iPullRank, Schema App, JetOctopus, Princeton/Georgia Tech/Allen Institute GEO study, SparkToro / Similarweb, Quattr, Kevin Indig / Growth Memo, Search Engine Land.
Published April 2026 by Dotfusion. Dotfusion is a Certified B Corp digital agency specializing in headless CMS builds, enterprise content operations, and Answer Engine Optimization. dotfusion.com
This post was conceived and written by Chris Bryce with our stack of AI research agents doing the heavy lifting on sources and data. If you want to talk about enterprise web strategy, AEO, or content operations, talk to us. We love this stuff.